Accelerate Your Deployment Velocity with Feature flags
2,451 words · 13 min read

By Archie Cowan
Senior Prototype Developer for AWS global and strategic customers, former ITHAKA/JSTOR Chief Architect. Generative AI builder. Aspiring to do everything.
Make Small Iterative Changes
We wrote in How Many Deployments Amazon Does in a Day that your team is likely capable of deploying a million times in about 10 years with a little more than 55 engineers by making 2-3 changes per week per engineer to production. When you make that many changes per week, those changes likely aren't complete features. Complete features may have hundreds of small iterative changes of that size with contributions from many people. Depending on the architecture of your tech stack, those changes may span multiple tiers of your system: user interfaces, back-end services, and possibly even infrastructure.
How do you avoid exposing customers to incomplete work while making hundreds or more changes per week to your production environment?
Assumption
This writing makes the assumption that the process by which you release software to an environment, or deployment pipeline, is automated. If you don't yet have at least most of your deployment pipeline automated, that probably should take precedence over these recommendations to increase your throughput.
Environments
The traditional approach to keeping work in progress away from live users (in addition to many other good reasons) is graduating changes through a series of environments.

Developers frequently deploy changes to a dev server or sometimes this happens on personal computers. This environment is almost always broken in some way because this is where work in progress is developed. Testers work against the test environment to avoid the chaotic nature of testing against the engineers work in progress. Defects are tracked in a ticketing system for the engineers to repair. Once a feature is ready for users and all the defects are repaired, then that version of the software is tagged and shipped to production.
But, as a team size grows, this usually gets more complex. With a small team, the group is probably focused on shipping a focused set of features. When two or more teams begins working on different parts of the same product, those teams will want to isolate their work in progress so that there can be some stability for testers and also the engineers. Different teams will have their own long lived branches that are only merged to a main branch occasionally. This is where we begin to see the following model that includes multiple dev environments, a project environment for each team, a test environment, and finally the prod environment.
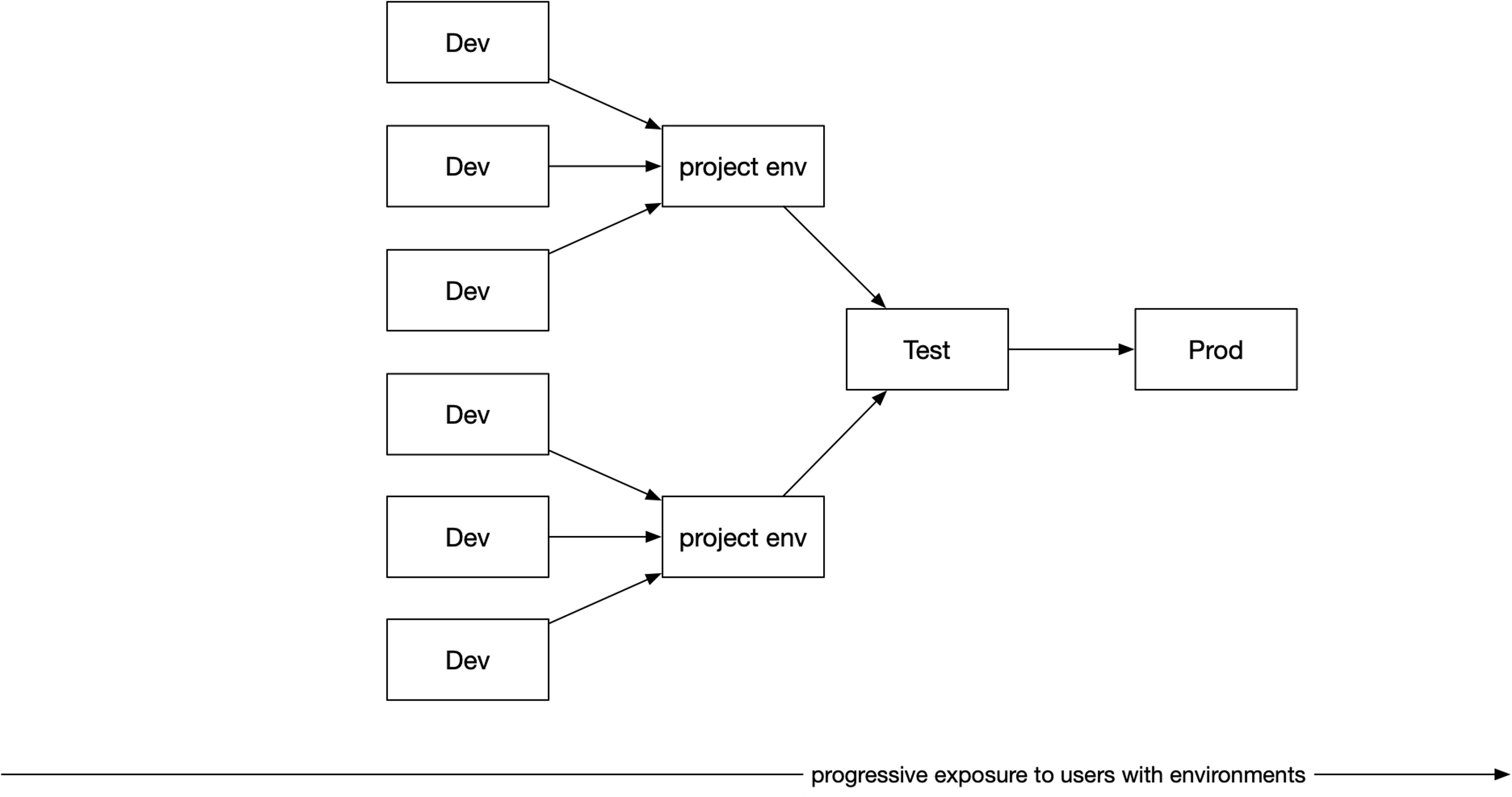
Some of you may see this as a simplification of your process. Maybe you have multiple test environments. A staging environment next to production. An environment only for demos to prospects. But, this is likely the same scaffolding.
Perhaps due to various constraints such as hardware costs or administrative overhead, only the Test environment is the highest fidelity copy of production. This drives a new constraint. Teams must negotiate for time on the test environment.
At this point, for a software release to ship to production, all of these things must have occurred:
- A feature or set of features is ready for customers
- Long lived branches are merged
- Defects and change conflicts across projects are resolved
- Time on test environments is scheduled
- Release for production is scheduled
Maybe a set of teams can manage their way through those procedures quickly enough to release once or twice a month. Certainly that process isn't enabling a production release 2-3 times per week per engineer. Just one of those steps could take a week by itself - like, merging a long lived branch to the main branch.
Also, the steps below were omitted which happen more often proportional to the size or number of changes. They happen frequently in this model:
- Defects or performance problems are discovered in production post release
- The prior version must be installed, if possible
- Defects are resolved
- Time is scheduled on the test environment
- Release to production after defects are repaired
Side Note: Deployment anti-patterns
The combination of a quarterly or monthly code update and high demand for changes from product will motivate your engineers to creatively build solutions outside of the main deployment pipeline. If engineers can only update code quarterly but also have a process for updating databases weekly, it's only a matter of time before your application has an embedded scripting runtime that can execute code stored in database tables. Just saying. We discuss this phenomenon more in deployment anti-patterns.
So far, we discussed the ways in which project teams use multi stage environments and long lived branches to batch changes together until new features are ready for customers. Next, we'll consider the benefits of layering feature flags on top of environments.
Feature Flags
Benefits and Motivation
What if we didn't need any of these steps to release to production?
- A feature or set of features is ready for customers
- Long lived branches are merged
- Defects and change conflicts across projects are resolved
- Time on test environments is scheduled
- Release for production is scheduled
What if we could release one change to production at a time? Would that help us reduce the impact and frequency of these post-release problems that drive unplanned work?
- Defects or performance problems are discovered in production post release
- The prior version must be installed, if possible
- Defects are resolved
- Time is scheduled on the test environment
- Release to production again
Elimination of the overhead of lots of work in progress and unplanned work is the objective of a what is often called a feature flag or feature switch or feature toggle.
- Eliminate project environments and the overhead to maintain them, everyone works in the same test environment 1
- Enable testing of incomplete features in the test environment and the production environment
- Eliminate long lived branches and large merges
- Eliminate full rollbacks when defects with a feature are discovered post release
Other benefits of feature flags include:
- Create new ways to demo upcoming product capabilities to your customers and stakeholders
- Reduce the risk of negative impacts to your customers driven by changes
- Your engineers are happier, increasing both retention and your ability to recruit
- Engineers working on test automation and product code will have new tools to coordinate
- You'll have new levers to manage unexpected traffic spikes by turning off nonessential features
- Positioning your teams to AB test functionality
What about Microservices?
The benefits of microservices do somewhat overlap with feature flags. Particularly when new functionality can be released to production with new services. In my experience, feature flags and micro-services are tangents. You can use them together and adopt either practice first.
Definition
So, what is a feature flag? The most basic form of a feature flag is essentially an
if statement predicated on whether a feature is enabled for the current request.if(featureFlags.isEnabled("feature-name", request)) {
// ... do something new here
}
Where
feature-name is a well understood label for the new feature and request represents an HTTP request (or whatever might be a request in your domain - a button clicked, an rpc call, etc). The request is expected to contain information regarding your user as well as other information such as their general location 2.The user should have a stable identifier assigned to their device or user account. Basically, the user identifier should enable you to deterministically identify a user across requests and possibly across multiple visits so that your user has a consistent experience.
The
featureFlags variable can be as simple as a map-backed structure that can answer questions of the catalog or registry of features available.The registry of features can be as simple as a JSON or CSV config file packaged with your software. Certainly, it can be more complex than that eventually. But, since we're talking about making small iterations, start small here and solve problems as they arise for you.
You'll likely find the following information in your feature registry helpful from the outset:
- a unique feature name
- a description of what it does
- a person or team who owns the flag and manages it long term
- a link to the ticket that initiated this feature in your project management system
- the list of conditions under which this feature is enabled
This information will give you traceability that you will need as your list of features grows. Whether this data is part of a database or in a file you can ship to production for rapid updates will depend on what capabilities are readily available in your environment. Being able to update it in low single digit minutes at the high end or less is recommended for this to be an effective risk management tool in production.
The
isEnabled function evaluates the list of conditions for the feature from the registry. These conditions will depend on your domain. However, the rules you'll likely need initially are these:- a feature is enabled because the user session indicates it should be enabled
- a feature is enabled for all users as indicated by the feature registry
These two conditions enable authorized users in your system to enable a feature for testing or demos as well as to enable a feature for all users.
The next most commonly desired condition in my experience is to enable a feature for a random percentage of users. For example, 5% of users, then 10% of users, then 25%, etc. This is one way to gradually expose your users to a new feature. Typically, I've done this with hashing. For example, the following pseudo code would enable you to increase exposure of a feature 1 percentage point at a time.
user.hash % numGroups < thresholduser.hashis an integer result from a hash function with a flat distribution such as md5, sha256, murmur, crc, etcnumGroupsdetermines the number of groups - your users will be in the same group as long as the hash returned is the same every time they visit your site and the number of groups doesn't changethresholdis the percentage of users you want to include - athreshold10andnumGroups100 would evaluate to true for 10% of users.
The biggest benefit to the hash function in this case is you can deterministically assign your users to groups without using any additional state.
Most platforms have built in libraries for hash functions. If you need to be able to evaluate the above expression on multiple platforms deterministically, this is also possible. Just know the way each of your libraries converts the bits returned by the hash function to integers and watch out for differences in platforms that may transparently provide you unsigned values and those that may not have unsigned types like Java.
Frequently asked questions about Feature Flags
Here are some relavant questions that might come up.
Why is it important to ship incomplete features to production?
- Every feature is built on many changes. Any one change could be one that makes your site unavailable. When you need to determine which change of 10s or 100s of changes caused an issue, it's going to increase your time to repair.
- Post release, when you know your code has been tested in all environments including production, you can have more confidence bringing that new feature to users.
- The drivers for long lived code branches go away. Incomplete work can merge to your main branch without impact to customers.
Do flags make automated testing more complicated?
- When you eliminate long lived branches in your product code you can also eliminate them in your test code. Same benefits apply to test code as product code.
- Flags give product and test engineers a point of coordination for their efforts. Test automation should be able to enable feature flags during the test setup phase of their suites so that test assertions are in alignment with features available.
- Overall reduction in work in progress means that test automation can start pretty much at the same time as product code iterations begin. This identifies defects and areas of the work that need better specification.
I find the above points eliminate many challenges test automation must face to be successful.
Should flagged code remain after the feature under construction is complete?
Flagged code can be awkward in applications that weren't designed with flags in mind. I've worked with systems that exceeded their complexity budget with only a few flags. I've also worked with systems with over 200,000 points of configuration with feature flags in production and they ran great. It depends on how much cognitive load an application puts on the engineers that need to maintain it. Systems that design with flags in mind can easily manage hundreds of flags if not scale to many thousands.
The additional benefit of leaving flags in place is that they can be disabled in production when needed. Perhaps an expensive feature threatens the availability of your system when a thundering heard of users from a news aggregator come to visit. Being able to disable the feature to preserve your availability would likely pay off the complexity of leaving the flag in place.
Flags should exist to help you manage risks. If flags become a risk then they've outlived their usefulness. Agree on a budget for how many flags your system should keep with your team. If the budget needs to increase or decrease over time, that's probably a good reason to refactor your system to manage the change.
Do flags need to control user visible features only?
No! Some of the best uses of flags are to facilitate backend work that isn't visible to customers. Maybe you are converting from one database to another and want to begin writing user profiles to both your old database and your new database and need to see real world effects of your most recent decisions. Or, maybe you have a new solution to replace an existing one and you want to substitute the new one for some users to see if it works better. Or, maybe you want to enable a feature for users without actually displaying the feature at all to understand how it behaves under real user load.
When should I not use feature flags?
If your release process is slow (monthly or longer), a feature flag may be a crutch for not making a decision. We have time before the next release, just build both features someone might say not knowing if one or the other will work. This is why flags should come into your organizational toolkit when you're able to release rapidly but can't because feature development doesn't get done that fast. The opportunity cost for building things you won't need is pretty high.
Recap
We've covered the basic definition of a feature flag and how using feature flags can help you accelerate your change velocity. Really hopes this helps you. Want to hear more about flags or how to introduce them to your systems? We'd love to hear from you, please reach out.
Footnotes
© 2021 - 2026 Archie Cowan